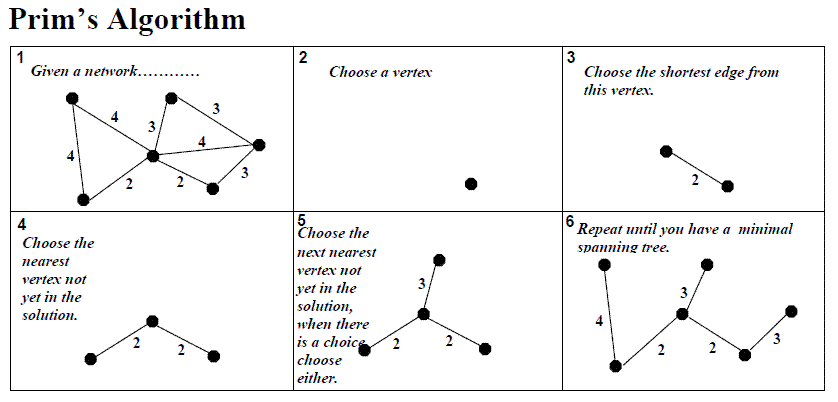
Chapter 6 Orthogonal Projection
6.1 Introduction








6.1 Introduction
- 範數
- 考慮 V 為一個向量空間(Vector space),則我們說 Norm 為一個函數滿足下列性質:
- 嚴格正定性: ||v||≥0, ||v||=0⇔v=0
- 正齊次性: 對所有的 α∈R,v∈V, ||αv||=|α|⋅||v||
- 次可加性:對任意 v1,v2∈V , ||v1+v2||≤||v1||+||v2|| (三角不等式)
- Norm為長度的推廣
- 下圖顯示不同P-範數的「單位圓」
- 正交相關
- 正交 (orthogonal) : 垂直這一直觀概念的推廣。作為一個形容詞,只有在一個確定的內積空間中才有意義。若內積空間中兩向量的內積為0,則稱它們是正交的。如果能夠定義向量間的夾角,則正交可以直觀的理解為垂直。
- 單範正交 (orthonormal) : 若每對向量均為正交且每個向量均為單位向量則稱S為單範正交。
- 正交集合為線性獨立 : 若S = {v1,v2,v3...vn}為內積空間V上一些非零向量所構成的正交集合,則S為線性獨立
6.2 Orthogonal Matrix
- Orthogonal Matrix
- 若 A^−1 = A^T 則稱 A 是正交矩陣,此時 A^TA = I。要驗證是不是正交矩陣,檢查 A^−1 = A^T 比較慢,算 A^TA = I 比較快
- 作為一個線性映射,正交矩陣保持距離不變,所以它是一個保距映射,具體例子為旋轉與鏡射。
- Gram-Schmidt process
- Gram-Schmidt正交化提供了一種方法,能夠通過這一子空間上的一個基得出子空間的一個orthogonal basis,並可進一步求出對應的orthonormal basis。在數值計算中,Gram-Schmidt正交化是數值不穩定的,計算中累積的捨入誤差會使最終結果的正交性變得很差。因此在實際應用中通常使用豪斯霍爾德變換或Givens旋轉進行正交化。
- 例題
- QR分解法
- QR分解法是三種將矩陣分解的方式之一。這種方式,把矩陣分解成一個半正交矩陣與一個上三角矩陣的積。QR分解的實際計算有很多方法,例如Givens旋轉、Householder變換,以及Gram-Schmidt正交化等等。
- 例題
6.3 Least Squares Solution
- least squares problem
- Ax = b為線性方程式系統
- 如果此系統為一致性,我們可以使用高斯消去法與反代法解x
- 當系統為不一致性時,如何找出最可能解,其中一個方法就是在Rn中找出使得Ax-b的範數||Ax - b||為最小的向量x 。這個定義即是最小平方問題的核心。
- least squares solution
- 對於任一線性系統Ax = b,這其所相對的Normal Equation為 A^TAx = A^Tb為一致性系統,且一般方程式的所有解是Ax=b 的最小平方解。
- 假如W是A的行空間,且x是Ax=b 的任一最小平方解,則b正交投影到W是projwb = Ax,若A為一具有線性獨立行向量之mxn的矩陣,則對於每一個mx1的矩陣b,線性系統 Ax=b 有一唯一最小平方解。
- Normal Equation 求 least squares solution的幾何意義
- Ax=b想要有解,b必須落在Ax的column space中。
- b 若不落在Ax的column space中,至少b的投影 projection必然落在此空間當中。
- 試圖尋找x使得Ax-b的長度最小。上述誤差的最小值正好發生在誤差向量與A的column space垂直時,也就是說希望誤差向量落在A'的 null space。